
Durante el último año, medio sector tecnológico ha repetido la misma promesa: 2026 será el año de los agentes de inteligencia artificial. Google acaba de poner letra pequeña a esa promesa. Su división Google for Startups ha publicado una extensa guía técnica —Startup technical guide: AI agents— pensada para que las jóvenes empresas dejen de hablar de agentes y empiecen a construirlos de verdad. Son 64 páginas que, leídas con calma, revelan bastante más que un manual de instrucciones: dibujan la foto de hacia dónde se mueve toda la industria y, sobre todo, por qué tantos proyectos de IA prometen mucho y entregan poco.
En La Prensa IA la hemos leído entera. No vamos a reproducirla —es propiedad de Google y cualquiera puede descargarla gratis desde la fuente oficial—, pero sí merece la pena destilar sus ideas de fondo y traducirlas a un lenguaje que un fundador, un directivo o un curioso pueda aprovechar. Lo interesante de este documento no es que enseñe a programar; es que ordena, con criterio de ingeniería, un terreno que hasta ahora se movía a golpe de moda.

Un agente no es un chatbot (y confundirlos sale caro)
La primera lección de la guía es casi una advertencia. Un chatbot responde; un agente actúa. La diferencia no es de grado, es de naturaleza. Google describe el motor de un agente como un ciclo continuo de tres pasos: razonar (evaluar el objetivo y la situación actual), actuar (elegir y ejecutar la herramienta adecuada) y observar (leer el resultado de esa acción para decidir el siguiente paso). Ese bucle, repetido tantas veces como haga falta, es lo que permite a un agente completar una tarea de varios pasos sin que un humano lo lleve de la mano en cada momento.
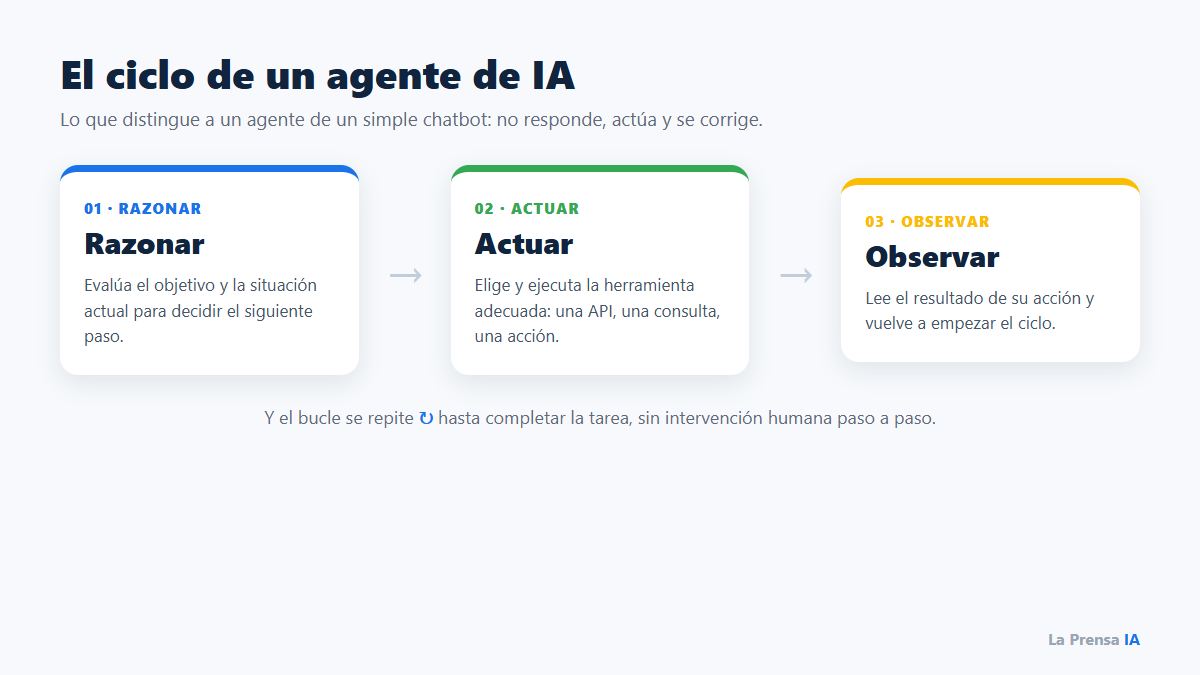
Parece un detalle técnico, pero tiene una consecuencia práctica enorme. Un asistente que solo conversa nunca podrá reservarte un vuelo, conciliar una factura o actualizar un CRM; un sistema que razona, actúa y observa, sí. Por eso la guía insiste en que el salto de valor no está en hacer que la IA hable mejor, sino en darle la capacidad de hacer cosas y de corregirse sobre la marcha.
Tres memorias, no una
Para que ese ciclo funcione, el agente necesita memoria. Y aquí la guía hace una distinción que muchos equipos pasan por alto: no existe una memoria, sino tres capas con funciones distintas.

La memoria de largo plazo es el conocimiento de base, lo que en la jerga se llama grounding: ancla al agente a información fiable y actualizada para que no se invente las respuestas. La memoria de trabajo sostiene el contexto de la conversación o tarea en curso y tiene que ser rapidísima, porque de ella depende que la experiencia resulte fluida. Y la memoria transaccional, la menos vistosa y la más decisiva, registra cada acción que el agente ejecuta para poder auditarla después. Sin un registro fiable de lo que el agente ha hecho, ninguna empresa seria puede confiarle una tarea con consecuencias reales.
Google añade un matiz que apunta al futuro inmediato: en lugar de arrastrar el historial bruto de cada conversación, conviene destilar la memoria. Su servicio gestionado Vertex AI Memory Bank lo hace de dos maneras: extrayendo automáticamente los hechos relevantes de un usuario a partir de sus conversaciones, o dejando que sea el propio agente quien decida, como si la memoria fuera una herramienta más, qué información merece guardarse. Quedarse con un puñado de datos esenciales en vez de con todo el historial es más escalable, más barato y, dice la guía, más “humano”.
El modelo es el cerebro, pero elegirlo bien es un arte
Si el agente tiene un cerebro, ese cerebro es el modelo de lenguaje. Y aquí la guía desmonta uno de los errores más caros del sector: pensar que el mejor agente es el que usa el modelo más potente. No lo es. Elegir modelo, dice Google, no consiste en escoger el más capaz, sino en encontrar el equilibrio óptimo entre tres variables que tiran en direcciones opuestas: capacidad, velocidad y coste.
Cuanto más potente es un modelo, más caro y más lento suele ser. El error más común —y el que más dinero quema en una startup— es sobreinvertir en capacidad para tareas que no la necesitan. La estrategia inteligente es justo la contraria: usar el modelo más eficiente para cada trabajo concreto. Llevado a un sistema con varios agentes, eso significa que no todos tienen por qué compartir el mismo cerebro: un modelo grande para el agente que razona sobre problemas complejos y modelos más ligeros y baratos para los que hacen tareas simples y repetitivas. La guía también recuerda que el fine-tuning —ajustar un modelo con datos propios— no está disponible en todos los casos: dentro del catálogo de Google se admite en la familia abierta Gemma y en versiones concretas de Gemini, y conviene revisar siempre la licencia antes de lanzarse.
Las herramientas son el verdadero superpoder
Si el modelo es el cerebro, las herramientas son las manos. Google es explícito: la credibilidad y la utilidad de un agente dependen, sobre todo, de su capacidad para usar herramientas externas. Una herramienta puede ser desde un simple cálculo interno hasta una llamada a una API que consulta una base de datos o lanza una operación en otro sistema. Son el puente entre lo que el agente piensa y lo que el agente puede hacer.
La guía distingue, entre otras, las funciones y servicios internos —la lógica propia que escribe tu equipo— y las APIs que conectan con servicios internos o de terceros. Un detalle revelador para quien programe: una herramienta bien diseñada debe devolver siempre una respuesta estructurada y predecible, de modo que el agente pueda interpretarla sin ambigüedad. Un agente brillante sin herramientas es, en el fondo, un orador elocuente atado a una silla.
De ahí que el documento dedique espacio a dos protocolos que se están convirtiendo en estándar para conectar agentes con el mundo y entre sí: MCP, que permite a un agente descubrir y usar herramientas de forma normalizada, y A2A (Agent2Agent), pensado para que varios agentes se comuniquen y se deleguen tareas. Es un detalle técnico con una lectura estratégica de primer orden: la industria está construyendo las “tuberías” para que los agentes dejen de ser islas y empiecen a trabajar en red.
De un agente a un equipo de agentes
La segunda parte de la guía es la más práctica, y su mensaje central resulta casi liberador para una empresa pequeña: el valor no está en construir un único agente perfecto, sino en orquestar varios. Google lo llama composición multiagente: sistemas donde distintos agentes especializados colaboran, se reparten el trabajo y se delegan tareas, como un pequeño equipo digital con sus roles bien definidos.
El documento describe varios patrones de colaboración que ayudan a entender la idea. En uno, un agente “padre” utiliza a otro agente como si fuera una herramienta: le encarga algo, recibe la respuesta y mantiene el control de la conversación. En otro, el padre cede el control por completo a un subagente especializado. Y para sistemas más complejos, donde los agentes viven en procesos o servidores distintos, entra en juego de nuevo el protocolo A2A, que permite que se entiendan entre ellos aunque no compartan código. La frase que mejor resume toda esta filosofía es contundente: automatiza flujos de trabajo, no solo conversaciones. Ahí está la palanca real para un equipo reducido: resolver problemas de negocio de varios pasos sin tener que contratar a diez personas.
El kit de Google (y por qué conviene leerlo con espíritu crítico)
Buena parte de la guía es, comprensiblemente, un recorrido por las herramientas del propio Google. Está el ADK, su kit de desarrollo de agentes, diseñado para que la lógica que escribes en Python sea independiente de dónde acabes desplegando el agente. Está Gemini CLI, un agente de código abierto que lleva las capacidades de Gemini directamente a la terminal para entender código, manipular archivos o depurar problemas, con integración en GitHub y en servicios como Firebase, BigQuery o Cloud Run. Y está Agentspace, pensado para gobernar y escalar una “plantilla” de agentes dentro de una organización, junto a la opción de desplegarlos en un runtime gestionado para no tener que preocuparse por la infraestructura.
Aquí conviene una advertencia que la propia naturaleza del documento exige: es la visión de Google y, como tal, empuja hacia su ecosistema. Nada que reprochar —es un material gratuito y de calidad—, pero el lector inteligente debe separar dos planos. Uno es la arquitectura que propone: razonar-actuar-observar, las tres memorias, la elección eficiente de modelos, las herramientas, la orquestación multiagente. Esa parte es universal y sirve se use la tecnología que se use. El otro plano son los productos concretos de Google que la implementan. Tomar lo primero y elegir con libertad lo segundo es, probablemente, la lectura más rentable de toda la guía.
La parte que casi nadie quiere oír: fiabilidad
La tercera sección es la que separa una demo vistosa de un producto que aguanta en producción, y es también la que más diferencia a esta guía de los típicos tutoriales entusiastas. Google la articula en torno a un concepto que va a ganar protagonismo en los próximos meses: AgentOps. La idea, heredera del ya conocido DevOps, es que un agente no se “termina” el día que funciona en una demostración, sino que se vigila, se mide y se corrige de forma continua mientras está vivo.
Eso se traduce en varias exigencias muy concretas. Una evaluación rigurosa y sistemática de la calidad de las respuestas, porque un agente es no determinista: ante la misma pregunta puede responder de formas distintas. Una observabilidad que permita seguir paso a paso la cadena de razonamiento y cada llamada a una herramienta, para poder depurar cuando algo falla. Y unas barreras de seguridad —los guardrails— que validen las instrucciones de entrada frente a posibles ataques de inyección y filtren las salidas para que el agente no diga ni haga algo dañino.
La guía va más allá de la teoría y describe cómo se operativiza todo esto: integrando esas comprobaciones de seguridad en el propio proceso de desarrollo, de modo que cada cambio de código se someta a pruebas automáticas antes de llegar a producción, y enviando la traza detallada de cada decisión del agente a un almacén seguro para conservar un registro auditable, imprescindible para revisiones de cumplimiento o para investigar un incidente. Aparece también, de forma recurrente, la figura del humano en el bucle (human-in-the-loop): para las acciones delicadas, el agente propone y una persona aprueba. Y una afirmación que conviene subrayar: la seguridad es una responsabilidad compartida; ninguna herramienta exime al equipo que construye el agente de pensar en los riesgos.
Qué significa todo esto para el ecosistema hispano
Para una startup española o latinoamericana, la lectura útil de esta guía no es técnica, es estratégica, y puede resumirse en cuatro conclusiones.
Primera: la barrera para construir agentes se ha desplomado, pero la barrera para construir agentes fiables sigue intacta. Cualquiera puede montar una demo impresionante en una tarde; muy pocos consiguen un agente en el que un cliente confíe su dinero o sus datos. Ahí, en la fiabilidad, es donde se gana o se pierde el negocio. Segunda: pensar en “equipos de agentes” en lugar de en un asistente todopoderoso encaja como un guante con equipos pequeños que necesitan multiplicar su capacidad sin multiplicar su plantilla. Tercera: la guía sugiere una vía clara para construir algo defendible —conectar los agentes a tus propios datos y APIs, eso que nadie más tiene—, en lugar de limitarse a poner una capa de conversación sobre un modelo que cualquiera puede usar. Y cuarta: los estándares abiertos como MCP y A2A son una buena noticia para quien no quiere quedar atrapado de por vida en un único proveedor.
El documento se cierra con una idea que resume bien su tono: el desarrollo de agentes representa un cambio de paradigma en la ingeniería de software, capaz de automatizar flujos complejos y resolver problemas antes inviables, pero pasar de un prototipo prometedor a un producto de verdad obliga a resolver retos nuevos. En el fondo, toda la guía es una invitación a tomarse los agentes en serio: menos hechizo y más ingeniería. Quien quiera bajar al detalle técnico —diagramas, ejemplos y el paso a paso— puede descargar el documento original, gratuito, directamente desde la página oficial de Google for Startups.
La Prensa IA no reproduce ni redistribuye el documento de Google; este artículo es un análisis propio elaborado por nuestra redacción a partir de la lectura de la guía. Todos los derechos del documento original pertenecen a Google.
Fermín Sánchez es el responsable editorial de LaPrensaIA, diario de divulgación sobre inteligencia artificial. Cubrimos la actualidad de la IA con criterio propio —tecnología, empresas y sociedad— de forma clara para el público no técnico. Cada artículo se elabora con la asistencia tecnológica de Iberia y se revisa antes de publicarse. Más sobre cómo trabajamos →
